Species distribution model selection
StatnMap - Sébastien Rochette
2021-03-26
Source:vignettes/SDM_Selection.Rmd
SDM_Selection.RmdOutlines
This library has been created for model selection to predict species distributions (Biomass, density or presence/absence). Its final aim is to produce maps of predicted distributions.
In this vignette, we use datasets from library dismo to show the different possibilities of the library with species distribution modelling, from model selection to predictive mapping. Dataset bradypus contains geographic position of species occurence. The different model types available in library ModelSelect to predict probability of presence all rely on presence/absence data. As the dataset only contains presence data, we need to create a pseudo-absence set of observations. Here, we do not discuss this method. We just imagine that we have a dataset of real observations of presence and real observations of absences, so that we can use presence-absence models.
We create a variable of interest (Obs) with presences (1) and absences (0). This is in accordance with our data modelling case datatype = "PA" and its sub-cases. For other types of data, refer to the documentation (in particular, options in modelselect_opt) to correctly set your modelling parameters.
*Note that most figures of the vignette are saved in “inst” so that model selection is not run during vignette building. However, code in the vignettes can be run on your own computer and should return the same outputs. To do so, open and run this Rmd file: /Users/runner/work/_temp/Library/SDMSelect/SDM_Selection/SDM_Selection.Rmd.*
Covariates
Covariates are environmental covariates that will be used to predict distribution of the species. In this vignette, we use raster already prepared from package dismo. This means that all rasters have the same projection, extent and resolution and can be stacked into a multi-layer Raster. In this case, they can directly be stacked together. If this is not your case, you can use function Prepare_r_multi to reproject, resample, crop all rasters of covariates to the dimensions of a reference raster (if needed). You only need to provide a vector of all paths to these rasters. Rasters representing factors / categories (like biome.grd here), should be resampled using nearest neighbour method (if they need to be resampled), thus they have to be declared with is.factor option.
# World map for plots
data(wrld_simpl, package = "maptools")
# Vectors of paths to rasters of covariates
covariates.paths <-
list.files(file.path(system.file(package = "dismo"), 'ex'),
pattern = 'grd$',
full.names = TRUE)
# Here covariates <- stack(covariates.paths)
# would have been enough for this specific case.
is.factor <- grep("biome.grd", covariates.paths)
covariates <- Prepare_covarStack(cov.paths = covariates.paths,
is.factor = is.factor)
print(covariates)## class : RasterStack
## dimensions : 192, 186, 35712, 9 (nrow, ncol, ncell, nlayers)
## resolution : 0.5, 0.5 (x, y)
## extent : -125, -32, -56, 40 (xmin, xmax, ymin, ymax)
## crs : +proj=longlat +datum=WGS84 +no_defs
## names : bio1, bio12, bio16, bio17, bio5, bio6, bio7, bio8, biome
## min values : -23, 0, 0, 0, 61, -212, 60, -66, 1
## max values : 289, 7682, 2458, 1496, 422, 242, 461, 323, 14Dataset
A presence-absence dataset is created from dataset bradypus in library dismo. Dataset is transformed as SpatialPointsDataFrame and spatially joint with covariates. Here, all covariates rasters have originally the same projection, extent and resolution. Covariates information can then directly be extracted from the covariates RasterStack with raster::extract(covariates, data.sp). However, if your covariates Rasters have originally different projection, you should extract covariate information at your data positions from these original rasters. Indeed, reprojection of raster leads to modification and potential loss of the original information. It is recommended to reproject the point data stations to extract covariates from their projection of origin. Function CovarExtract does this task for you.
# Presence data
file <- file.path(system.file(package = "dismo"), "ex/bradypus.csv")
bradypus <- read.table(file, header = TRUE, sep = ',')[,-1]
# Random-absence data
randAbs <- dismo::randomPoints(covariates, 400)
colnames(randAbs) <- c("lon", "lat")
# Combine presence and absence
data.sp <- rbind(data.frame(randAbs, Obs = 0),
data.frame(bradypus, Obs = 1)
)
# Transform data as SpatialPointsDataFrame
sp::coordinates(data.sp) <- ~lon+lat
sp::proj4string(data.sp) <- "+proj=longlat +datum=WGS84"
# Extract covariates, combine with dataset and set factor covariate
data <- CovarExtract(x = data.sp, cov.paths = covariates.paths,
is.factor = is.factor)| Obs | bio1 | bio12 | bio16 | bio17 | bio5 | bio6 | bio7 | bio8 | biome |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 264 | 3333 | 1382 | 325 | 336 | 204 | 132 | 256 | 1 |
| 0 | 265 | 2269 | 1008 | 269 | 326 | 214 | 113 | 261 | 1 |
| 0 | 242 | 217 | 152 | 4 | 365 | 104 | 262 | 307 | 13 |
| 0 | 262 | 2212 | 996 | 190 | 330 | 211 | 119 | 258 | 1 |
| 0 | 262 | 831 | 328 | 88 | 323 | 202 | 121 | 281 | 2 |
| 0 | 210 | 1610 | 477 | 282 | 322 | 99 | 223 | 227 | 1 |
# Show observations positions
par(mar = c(1,1,1,1))
raster::plot(covariates, "bio1")
sp::plot(wrld_simpl, add = TRUE)
sp::plot(data,
col = c("red", "blue")[data@data$Obs + 1],
pch = 20, cex = c(0.5, 1)[data@data$Obs + 1],
add = TRUE)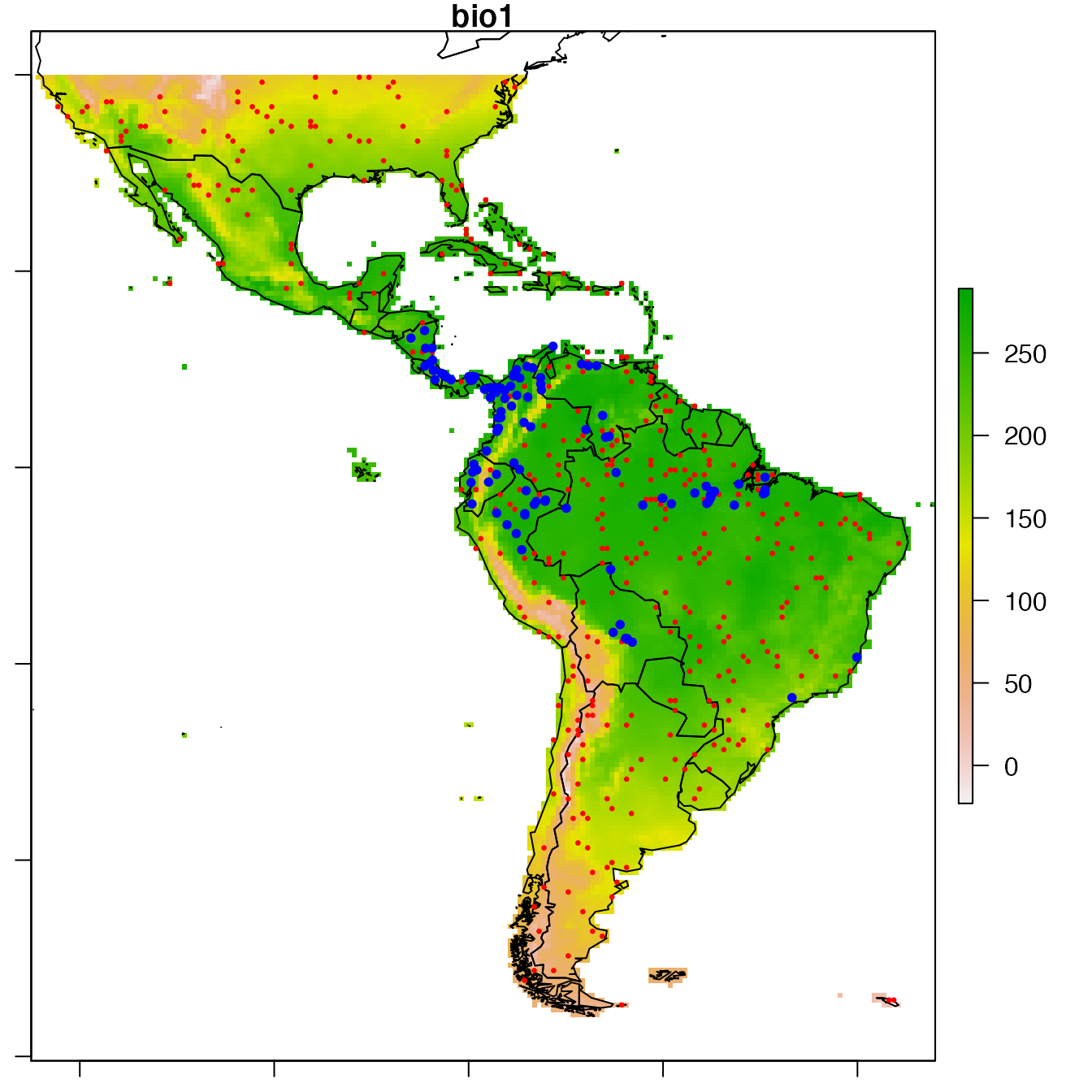
Prepare the spatial dataset for modelling
The first step only consists in changing observation column name to dataY and append factor column names with factor_ for compatibility with following functions.
data.prepared <- Prepare_dataset(
x = data, var = 1, cov = 2:ncol(data),
datatype = "PA", na.rm = TRUE
)## class : SpatialPointsDataFrame
## features : 515
## extent : -122.25, -35.75, -54.75, 39.75 (xmin, xmax, ymin, ymax)
## crs : +proj=longlat +datum=WGS84 +no_defs
## variables : 10
## names : dataY, bio1, bio12, bio16, bio17, bio5, bio6, bio7, bio8, factor_biome
## min values : 0, -4, 1, 1, 0, 67, -119, 78, -49, 1
## max values : 1, 282, 7682, 2458, 1496, 415, 236, 447, 320, 9The random-absence dataset was deliberately created with a lot of stations. A high number of observations may lead to spatial auto-correlation that may interfere with modelling. We can simplify the dataset by resampling in a regular grid with a resolution partially reducing spatial-autocorrelation.
Function spatialcor_dist helps define an optimal grid resolution for this purpose. There may be different depth of spatial auto-correlation in the dataset. Function spatialcor_dist allows comparing two levels using two maximum distances max1 and max2. Two correlograms are calculated on the dataset based on these maximum values. A linear threshold model is fitted to find a possible threshold in correlation. This threshold value can be used for resampling in a regular grid having this value as a resolution.
thd <- spatialcor_dist(
x = data.prepared, longlat = !is.projected(data),
binomial = TRUE, saveWD = tmpdir,
plot = TRUE,
figname = "Correlogram"
)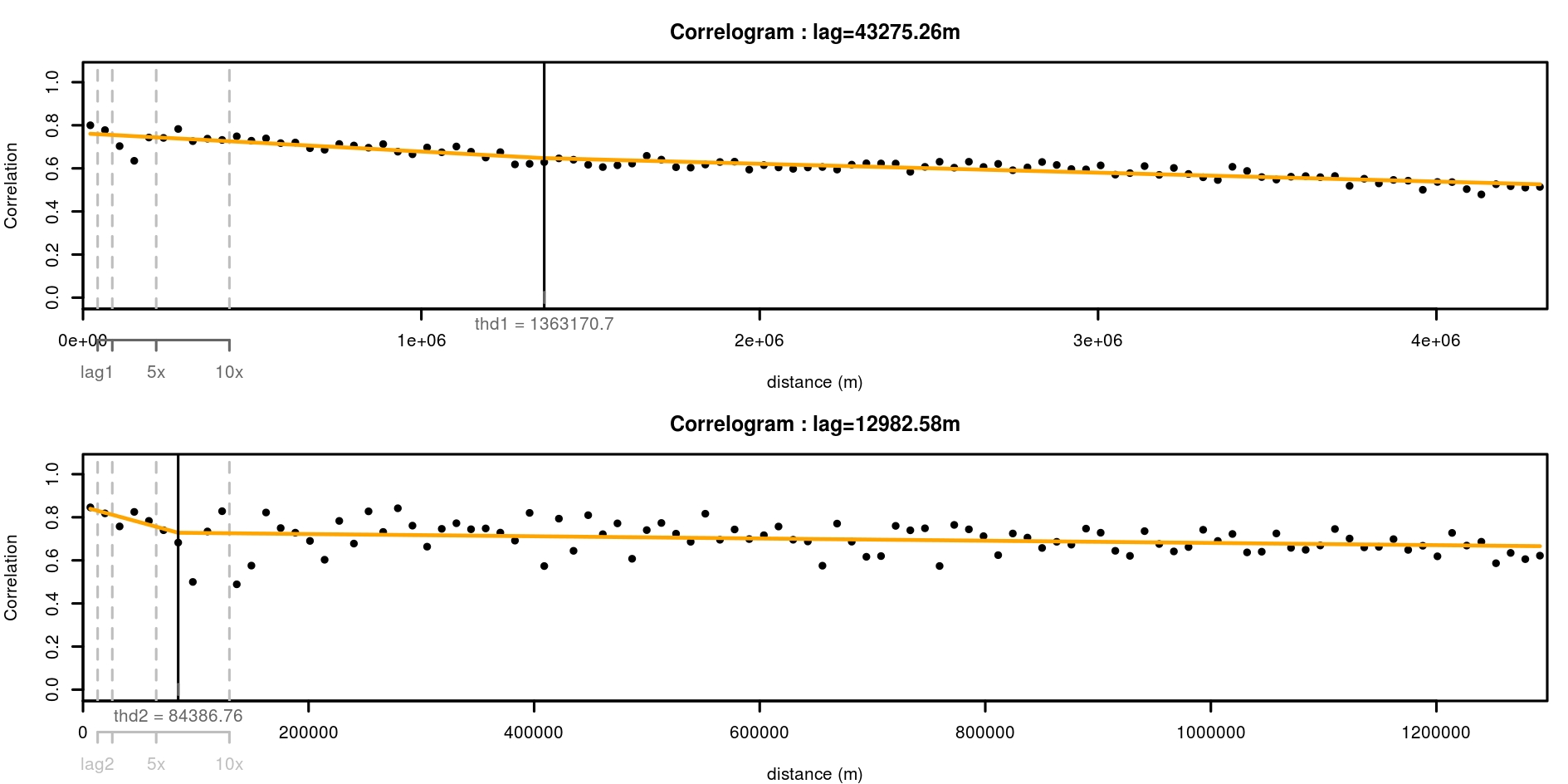
We choose a resolution for resampling the data using proposition of spatialcor_dist function. Here, thresholds estimated are 1363km and 84km. The second value is used to build a regular grid, with which the spatial dataset is resampled. Function RefRasterize allows creating a grid with a defined resolution. Function Prepare_dataset is then re-run to create the new dataset passed through the grid. For all observations in the same grid cell, the function calculates the average spatial position, the average of all numeric covariates, the most frequent factor covariate, observation of presence if the species was present at least once in the cell (the mean of observations when continuous data). data.new output is a SpatialPointsDataFrame.
# Create a regular grid from dataset
RefRaster <- RefRasterize(x = data, res = round(thd[2]))
# Use rectangular grid to resample dataset
data.new <- Prepare_dataset(
x = data.prepared, var = 1, cov = 2:ncol(data),
RefRaster = RefRaster, datatype = "PA", na.rm = TRUE
)
# Plot data.new
par(mar = c(1,1,1,1))
raster::plot(covariates, "bio1")
sp::plot(wrld_simpl, add = TRUE)
sp::plot(data.new,
col = c("red", "blue")[data.new@data$dataY + 1],
pch = 20, cex = c(0.5, 1)[data@data$Obs + 1],
add = TRUE)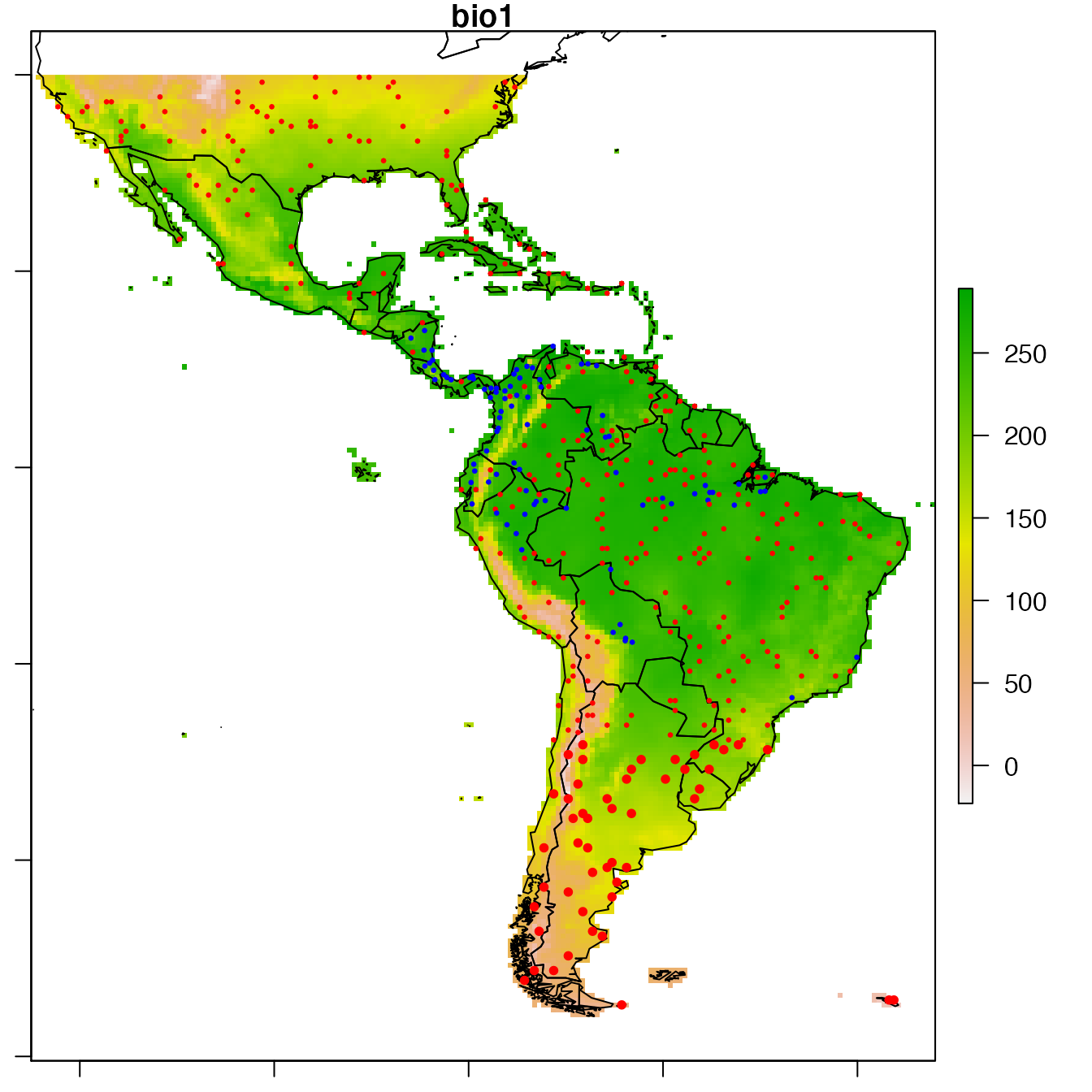
Covariates correlation
Due to identifiability issues, highly correlated environmental covariates should not be included in the same models. Correlations between all possible pairs of covariates are tested using the Spearman’s rho coefficient. Here, a rho value exceeding 0.7 considers covariates too correlated to be included in the same model. However, the following cross-validation procedure also guarantees too correlated covariates not to be included in the same models as gain in prediction may be low. Thus, the present covariates correlation selection step mainly allows the number of tested models to be reduced.
corSpearman <- Param_corr(
x = data.new, rm = 1, thd = 0.7, visual = FALSE,
plot = TRUE, img.size = 8, saveWD = tmpdir)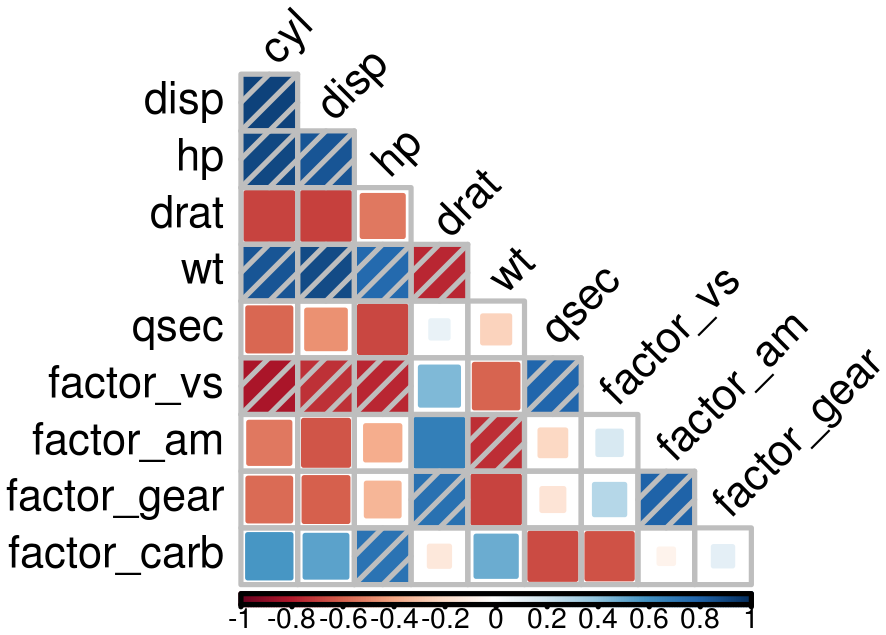
Find the best combination of covariates
Set options for presence-absence models. Have a look at options documentation ?modelselect_opt.
modelselect_opt(RESET = TRUE)
modelselect_opt$Max_nb_Var <- 3
modelselect_opt$datatype <- "PA"Procedure selects combination of covariates in each iteration from one covariate to the maximum defined (modelselect_opt(“Max_nb_Var”) = 3). This reproduces the procedure separately for all model types defined (modelselect_opt(“modeltypes”) = PAGLM, PAGLMns, PA). The output of findBestModel function is the link to a zipped file of all outputs saved in the saveWD directory. Messages in the console shows the steps of the iterative model selection procedure.
res.file <- findBestModel(x = data.new, datatype = "PA",
corSpearman = corSpearman,
saveWD = tmpdir,
verbose = 1)Order models according to quality of prediction
Model selection was realised separately for each distribution tested. The exact same k-fold cross-validation datasets have been used to keep the best model at each step of the iteration procedure. All indices of goodness of fit can thus be compared among the distributions tested with paired statistical tests. This allows to order all models tested. The best model and the following ones not statistically worse than the best one (one-sided p-value >= modelselect_opt$lim_pvalue_final) are retained.
# Order models and find the bests
BestModels <- ModelOrder(saveWD = tmpdir, plot = TRUE)This results in figures showing the distribution of the goodness of fit (here AUC) issued from cross-validation for each model. This allows to see that predictive power of some models is not very different than the best one. Coloured boxplots are those of AUC distribution not statistically different from the best one. Models are ranged by family chosen and number of covariates added during the forward stepwise procedure.

Two tables are available:
- “VeryBestModels_crossV” retains the best model and the ones not significantly worse than the first one.
| Num | model | Mean_AUC_crossV | Mean_RMSE_crossV | AIC | modeltype |
|---|---|---|---|---|---|
| 42 | dataY ~ s(bio16,k=5) + s(bio5,k=5) + s(bio1,k=5) | 0.88 | 0.32 | 282 | PA |
- “BestForModeltypes” retains the first two best models of each “modeltype”.
| Num | model | Mean_AUC_crossV | Mean_RMSE_crossV | AIC | modeltype |
|---|---|---|---|---|---|
| 42 | dataY ~ s(bio16,k=5) + s(bio5,k=5) + s(bio1,k=5) | 0.88 | 0.32 | 282 | PA |
| 43 | dataY ~ s(bio6,k=5) + s(bio5,k=5) + s(bio12,k=5) | 0.86 | 0.34 | 302 | PA |
| 15 | dataY ~ bio12 + bio6 + poly(bio5,3) | 0.86 | 0.34 | 308 | PAGLM |
| 16 | dataY ~ bio12 + bio6 + poly(bio5,2) | 0.86 | 0.34 | 310 | PAGLM |
| 27 | dataY ~ ns(bio7, df=2) + ns(bio5, df=3) + ns(bio8, df=2) | 0.84 | 0.35 | 320 | PAGLMns |
| 23 | dataY ~ ns(bio7, df=2) + ns(bio5, df=3) | 0.84 | 0.35 | 320 | PAGLMns |
Covariates selected in all models not statistically different from the best one may be explored to choose the best model by expertise. Covariates are ordered based on occurrence in the models selected. You may want to choose between the best model and the model with most selected covariates.
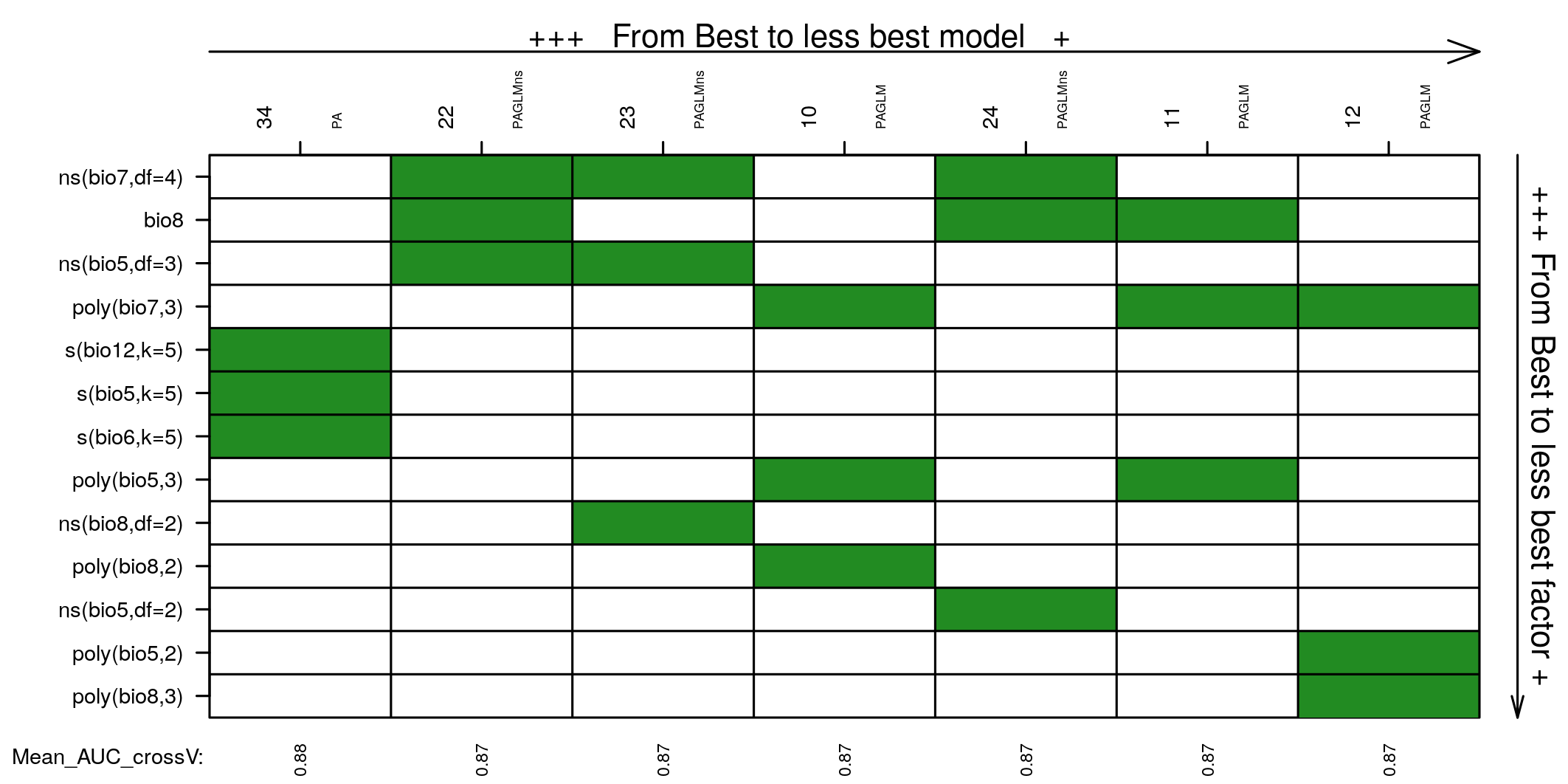
Predictions of the best model
We can choose one model, the best one here, and create a set of figure outputs to explore what it is predicting. Figures are saved in saveWD and its compressed version (its path is the output of the function, here stored in res.file)
Num.Best <- BestModels$VeryBestModels_crossV$Num[1]
res.file <- ModelResults(saveWD = tmpdir, plot = TRUE,
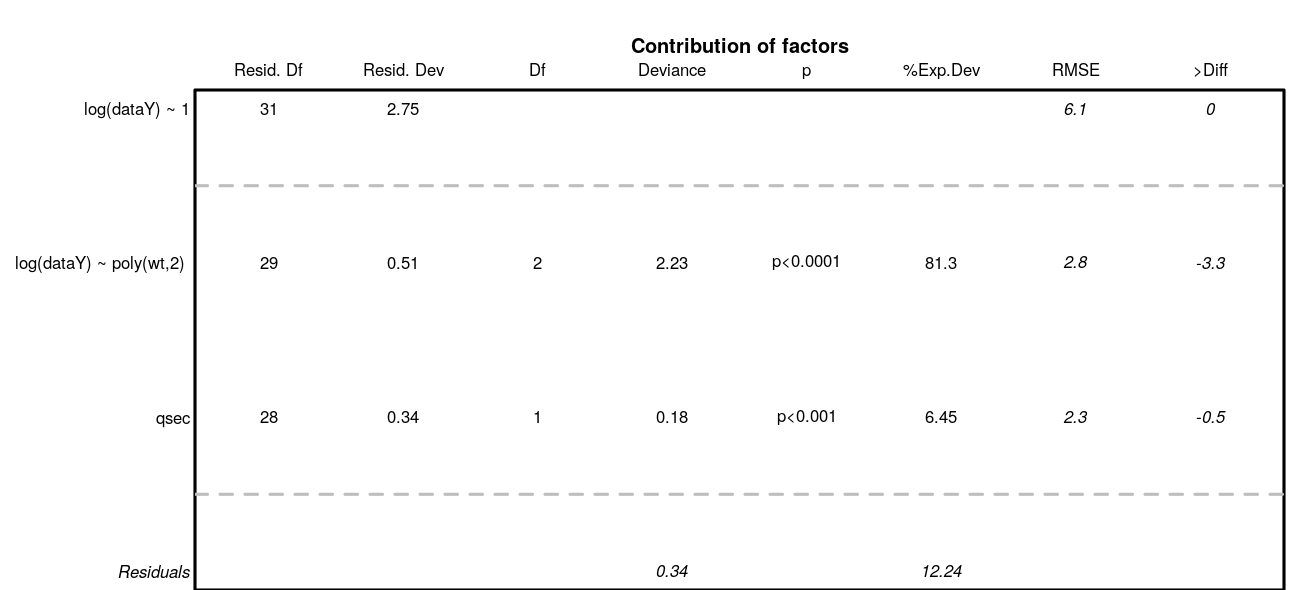
Num = Num.Best)In the case of a model with presence-absence, the outputs are the following.
Analysis of variance. Deviance explained by each covariate when added sequentially in the order specified by the cross-validation procedure. “%Exp.Dev” stands for percentage of explained deviance. “AUC” is the mean AUC on the validation datasets as issued from the cross-validation procedure, “>Diff” being the difference of cross-validation AUC with the previous step.
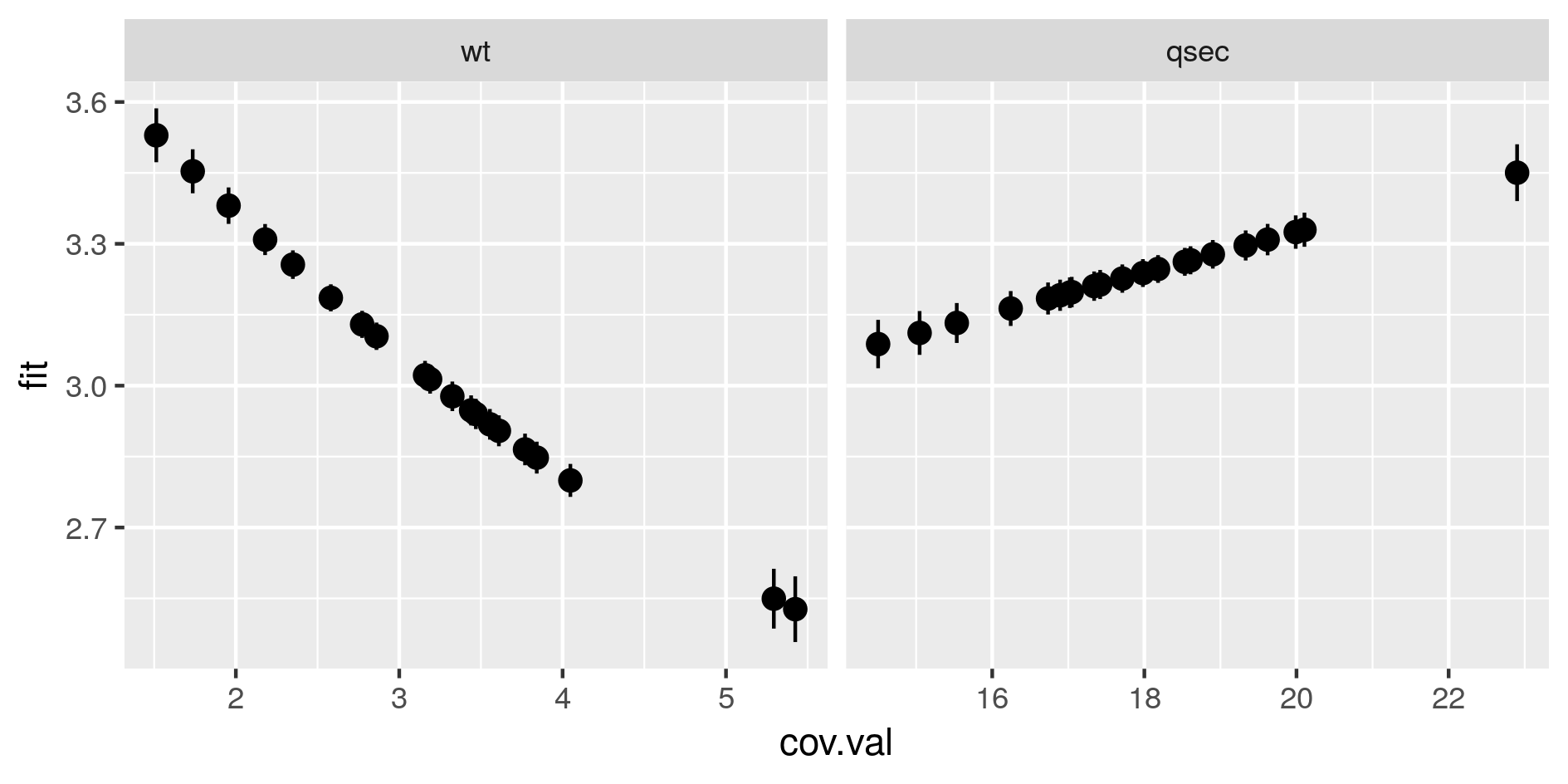
Marginal predictions by covariates. These are simplified marginal effects of each covariate in the range of observations. All covariates values except one have been fixed so that their combination give a prediction close to the mean of observations. These simplified marginals figures are to be read for their relative effect and not for their absolute prediction.
-
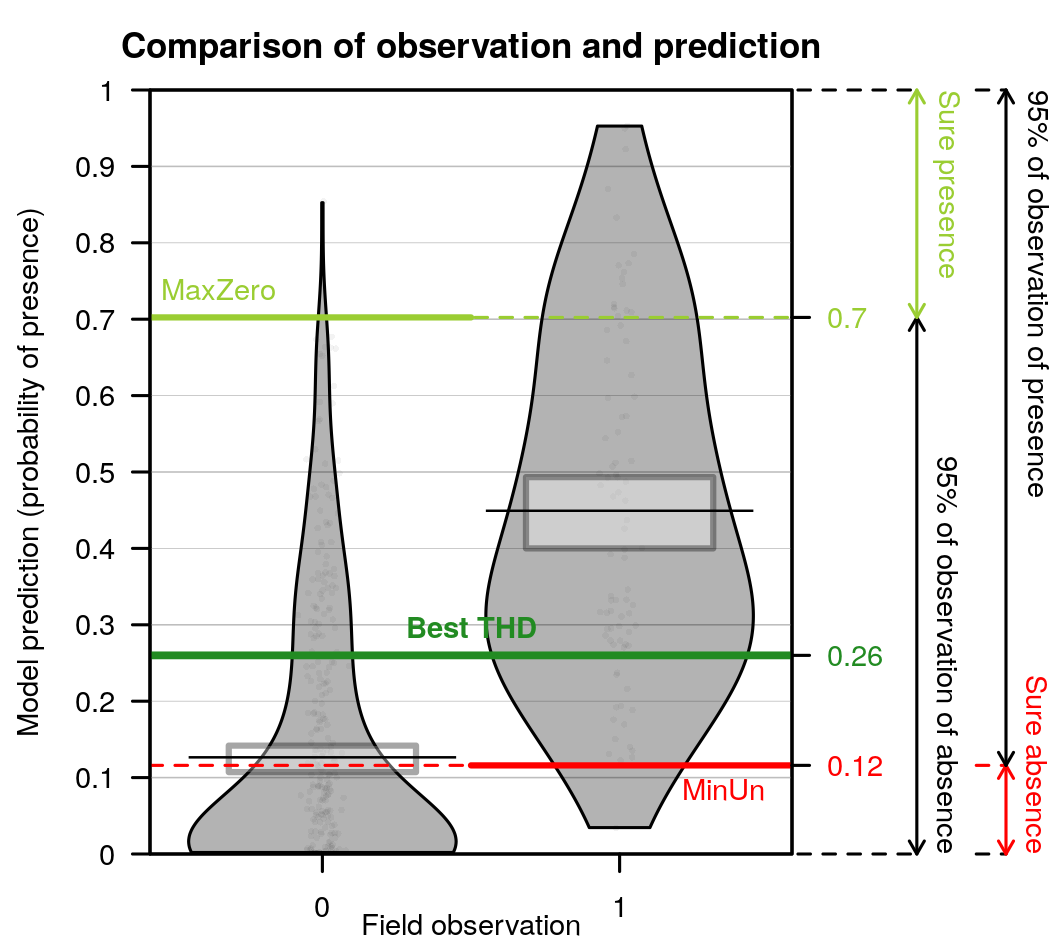
Comparison of predictions against observations and proposition of threshold values to separate presence from absences. The best threshold value is based on cross-validation outputs. This is the value closest to selectivity equals specificity.
- When the best model has been selected, it is used for prediction. All data are used to fit the model, predictions are made on the same dataset. For each observation, the model predicts a probability of presence between 0 and 1, although observations were 0 or 1. The figure is a “pirateplot” from package {yarrr}. It shows the distribution of predictions for the best model separating presence-absences observed.
- The Bean plot is a smoothed density (inspired by Kampstra et al. (2008)).
- The (Bar/Line Center) shows the mean of the distribution
- The band represents an inference interval around the mean: Bayesian Highest Density Interval
- Other indices have been calculated during the cross-validation procedure.
- The best THD is the best threshold value to separate presences from absences considering quality of prediction of the model. Indeed, if the cross-validation built 10 times 10-fold cross-validation models, then there are 100 validations. For each of the 100 model, the best threshold is the value on the ROC curves that equilibrates selectivity and sensitivity of the predictions. The best THD on the figure is the average of the 100 cross-validation thresholds. (Best THD close to 0.5 shows well-balanced dataset with trustwirthy predictions. lower (resp. higher) value show a desequilibrium towards absences (resp. presences) in the combination of covariates selected)
- Similarly, MaxZero is the average of 100 cross-validation threshold calculated as the threshold below which 95% of absence are correctly classified as absences. (the closest to the best THD, the better)
- Similarly, MaxUn is the average of 100 cross-validation threshold calculated as the threshold above which 95% of presences are correctly classified as presences. (the closest to the best THD, the better)
- When the best model has been selected, it is used for prediction. All data are used to fit the model, predictions are made on the same dataset. For each observation, the model predicts a probability of presence between 0 and 1, although observations were 0 or 1. The figure is a “pirateplot” from package {yarrr}. It shows the distribution of predictions for the best model separating presence-absences observed.
Species distribution mapping
Probability of presence
The outputs of the best model can be used to predict species distribution. The model selected is coupled with the raster of covariates to predict a probability of presence in each cell of the raster. Function Map_predict returns a RasterStack with these predictions.
pred.r <- Map_predict(object = covariates, saveWD = tmpdir, Num = Num.Best)
predr <- system.file("SDM_Selection", "predr.tif", package = "SDMSelect")
pred.r <- raster::stack(predr)
predrNames <- system.file("SDM_Selection", "predrNames.rds", package = "SDMSelect")
names(pred.r) <- readr::read_rds(predrNames)The first output of interest is the first layer resp.fit of the RasterStack. Here, the predicted probability of presence. SDMSelect is provided with gplot_data, a modified version of rasterVis::gplot which allows to prepare a (part of) raster data for ggplot visualisation instead of visualizing it directly. Maybe useful in some situations.
# Get partial raster data to plot in ggplot
pred.r.gg <- gplot_data(pred.r)
# Plot
ggplot() +
geom_tile(
data = dplyr::filter(pred.r.gg, variable == "resp.fit"),
aes(x = x, y = y, fill = value)) +
scale_fill_gradient("Probability", low = 'yellow', high = 'blue') +
coord_equal()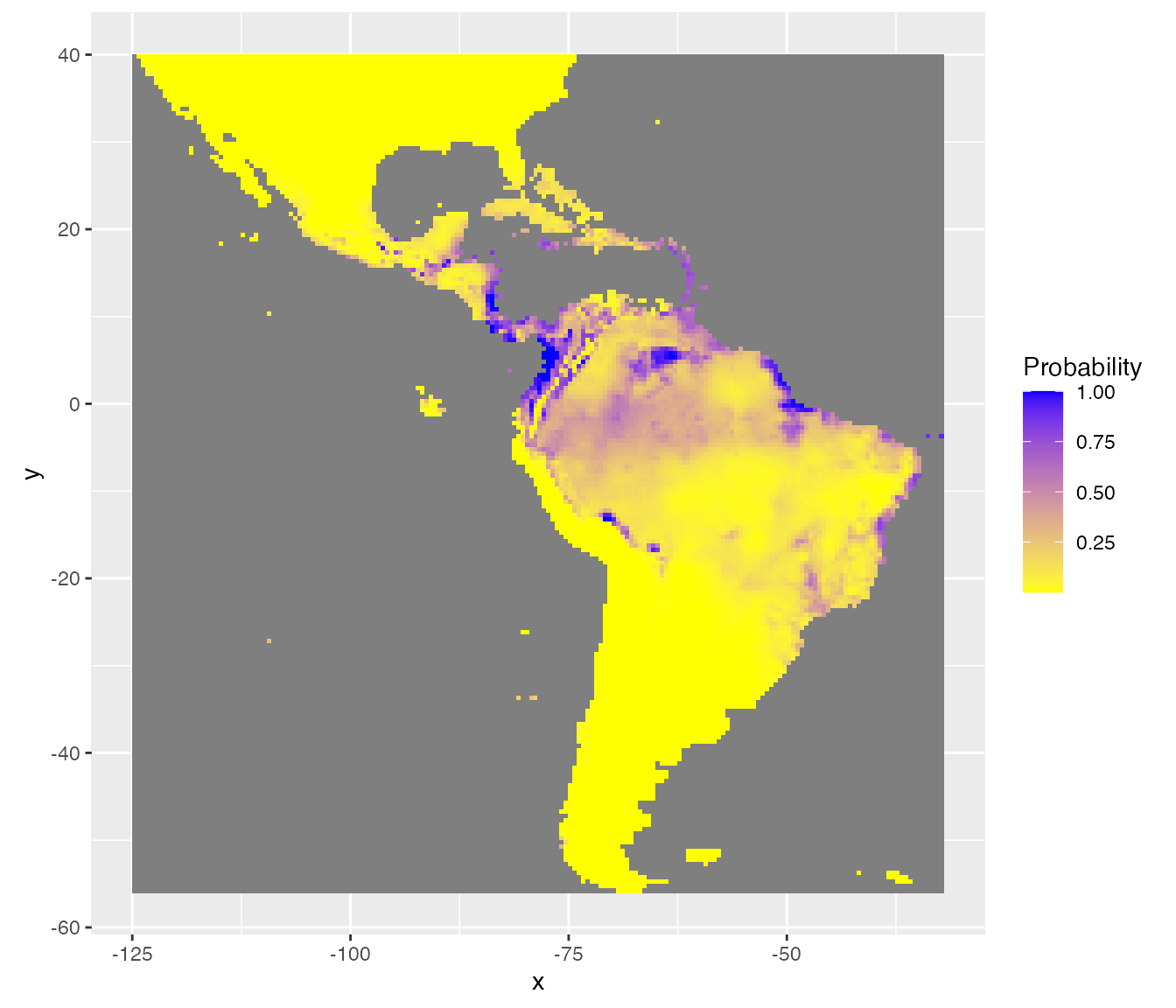
Uncertainties
Function Map_predict also calculates different indices for the assessment of the uncertainty of prediction. For instance, minimum (quantile = 5%) and maximum (quantile = 95%) of possible predictions. (This is based on quantiles predictions in the scale of the link function, then transformed in the scale of the response.)
rasterVis::gplot(raster::dropLayer(pred.r, which(!names(pred.r) %in% c("Q5", "Q95")))) +
geom_tile(aes(fill = value)) +
facet_grid(~variable) +
scale_fill_gradient("Probability", low = 'yellow', high = 'blue') +
coord_equal()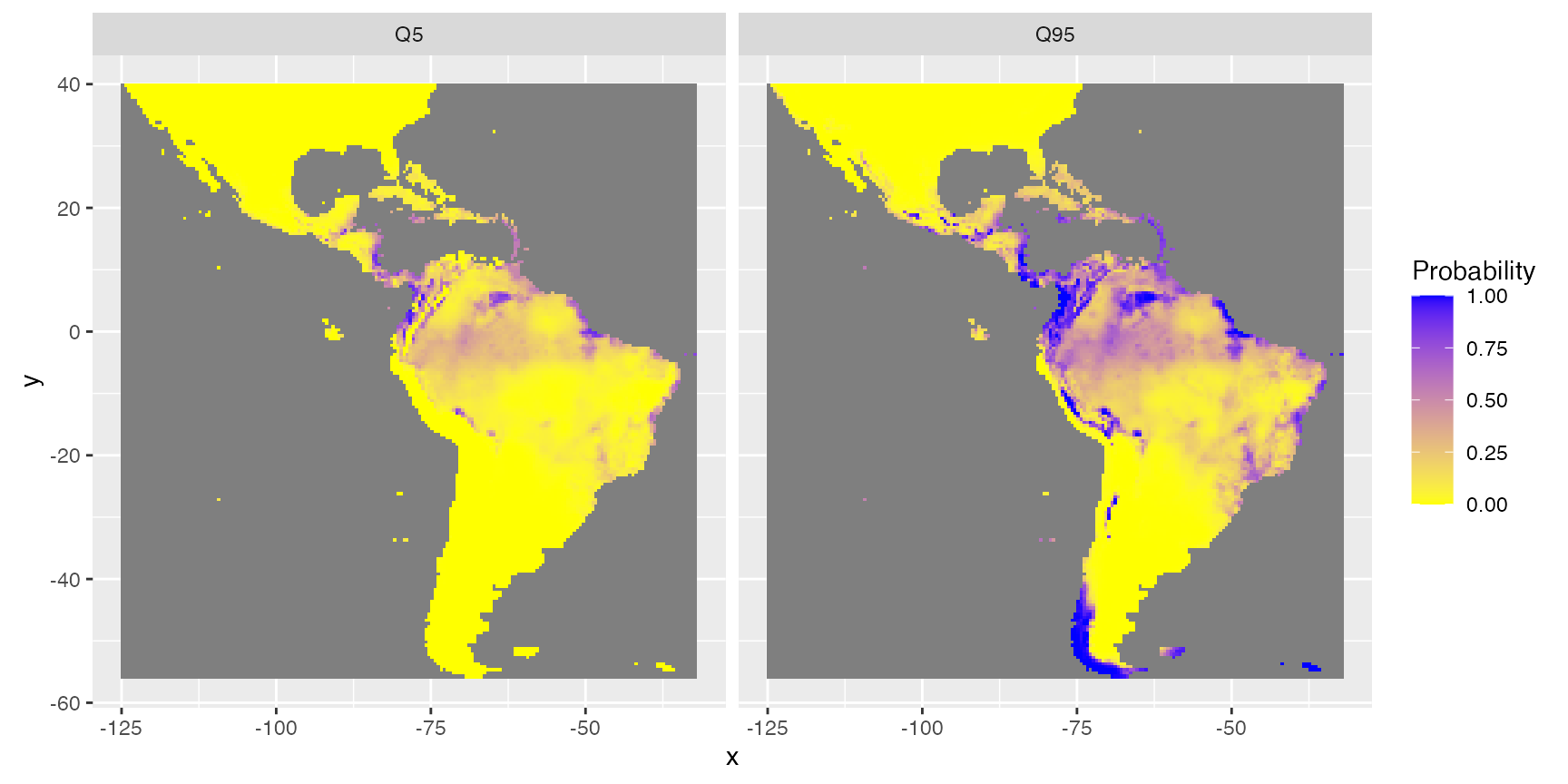
The inter-quartile range (IQR) and the IQR divided by the median (IQR.M) give an idea of the absolute and relative uncertainty of the predictions. This is similar to standard deviation and coefficient of variation respectively but better here because predictions are not Gaussian shaped.
rasterVis::gplot(raster::dropLayer(pred.r, which(!names(pred.r) %in% c("IQR")))) +
geom_tile(aes(fill = value)) +
facet_grid(~variable) +
scale_fill_gradient("Absolute\nDispersion", low = 'white', high = 'red') +
coord_equal()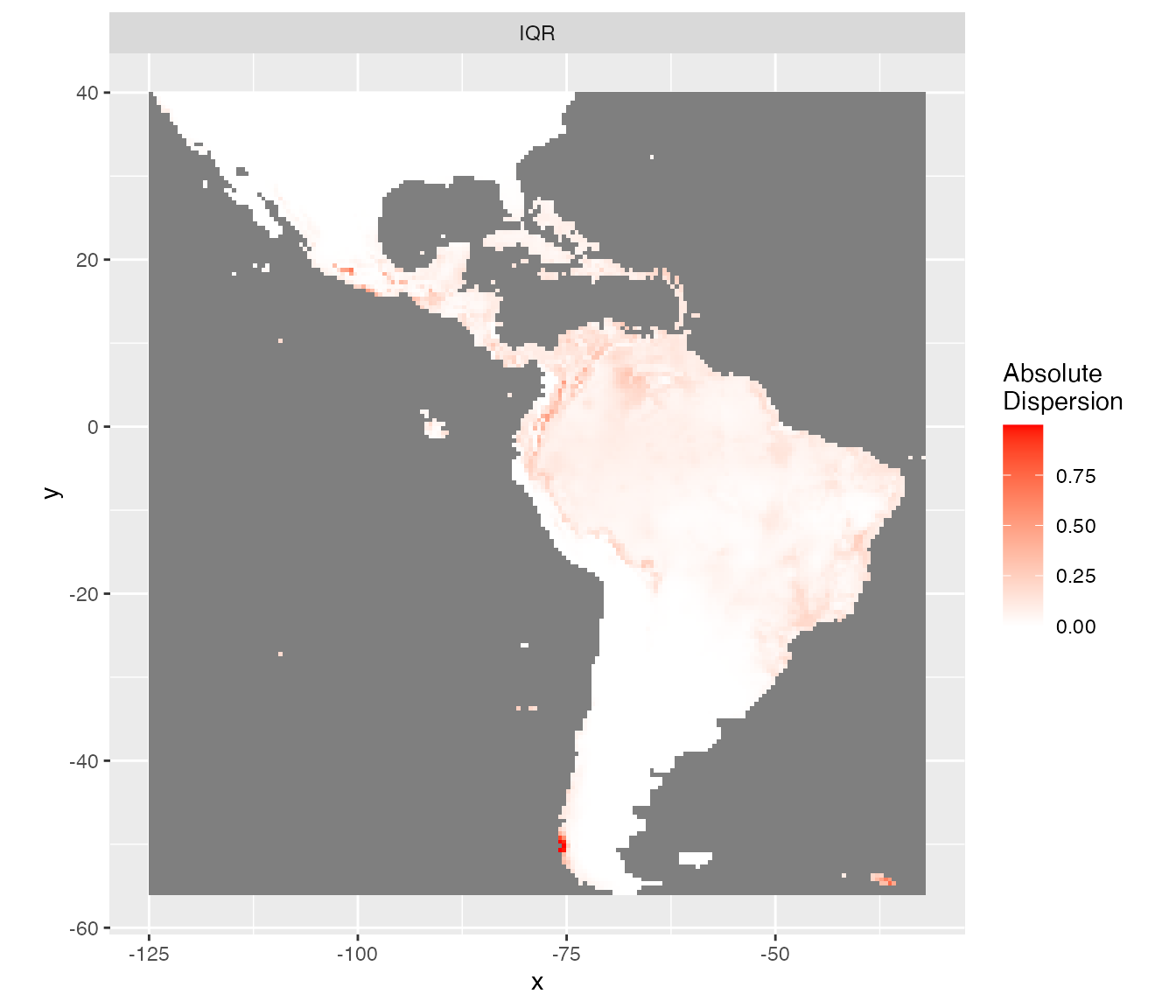
rasterVis::gplot(raster::dropLayer(pred.r, which(!names(pred.r) %in% c("IQR.M")))) +
geom_tile(aes(fill = value)) +
facet_grid(~variable) +
scale_fill_gradient("Relative\nDispersion\nto median", low = 'white', high = 'red') +
coord_equal()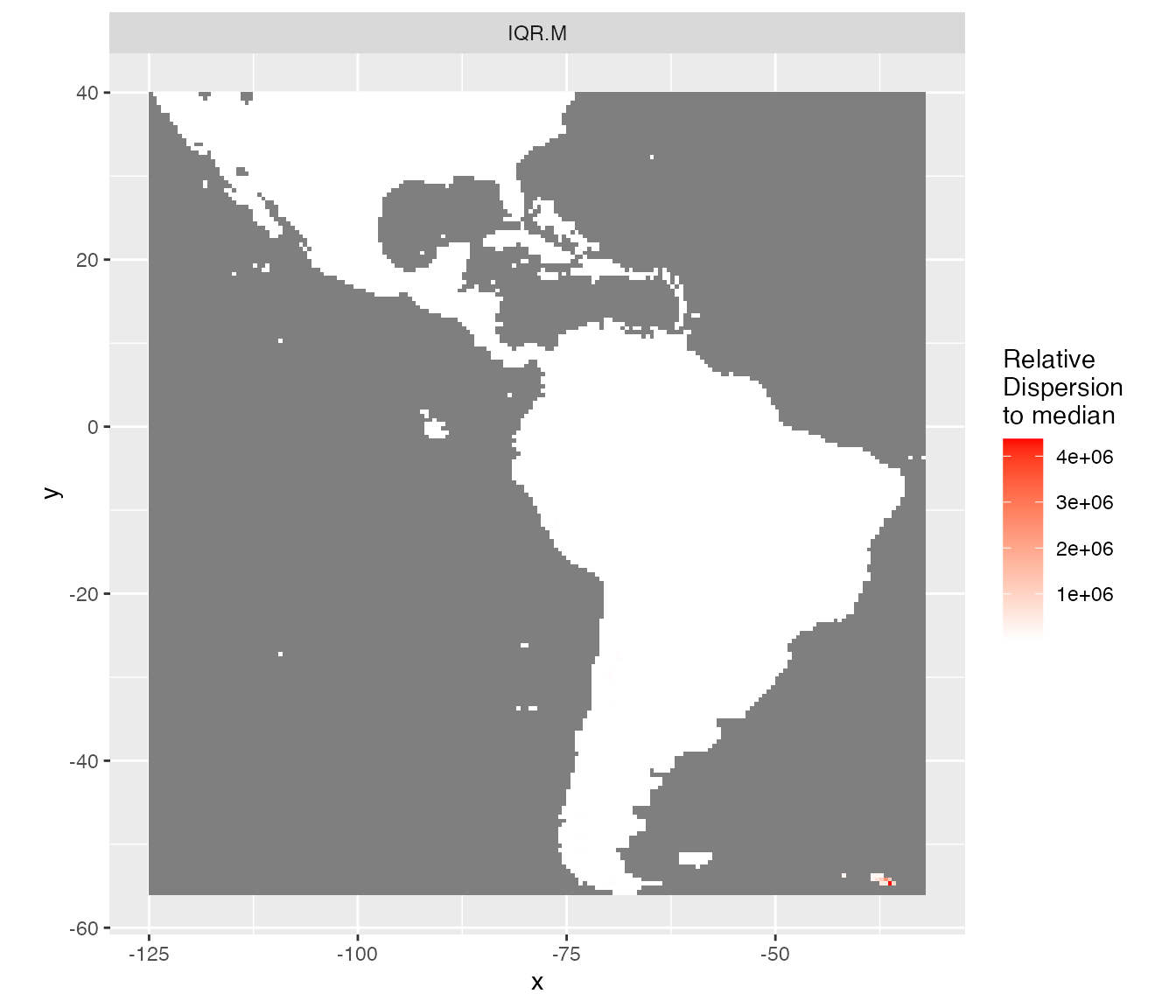
Separating presence from absences
The best threshold value to separate presences from absences may not be 0.5 when the presence/absence data are not equilibrated among covariates selected. The best threshold value (BestTHD) is shown above in the plot comparing observations and predictions. We can retrieve this value with function model_select.
model_selected <- model_select(
saveWD = tmpdir,
new.data = data.new,
Num = Num.Best)
BestThd <- model_selected$Seuil
BestThdFile <- system.file("SDM_Selection", "BestThd.rds", package = "SDMSelect")
BestThd <- readr::read_rds(BestThdFile)A better representation of the probabilities of presence should be with a double colour gradient, centred on the best threshold value (thd = 0.24).
rasterVis::gplot(raster::raster(pred.r, "resp.fit")) +
geom_tile(aes(fill = value)) +
scale_fill_gradient2("Probability\nof\nPresence",
low = 'white', mid = 'yellow', high = 'blue',
midpoint = BestThd) +
coord_equal()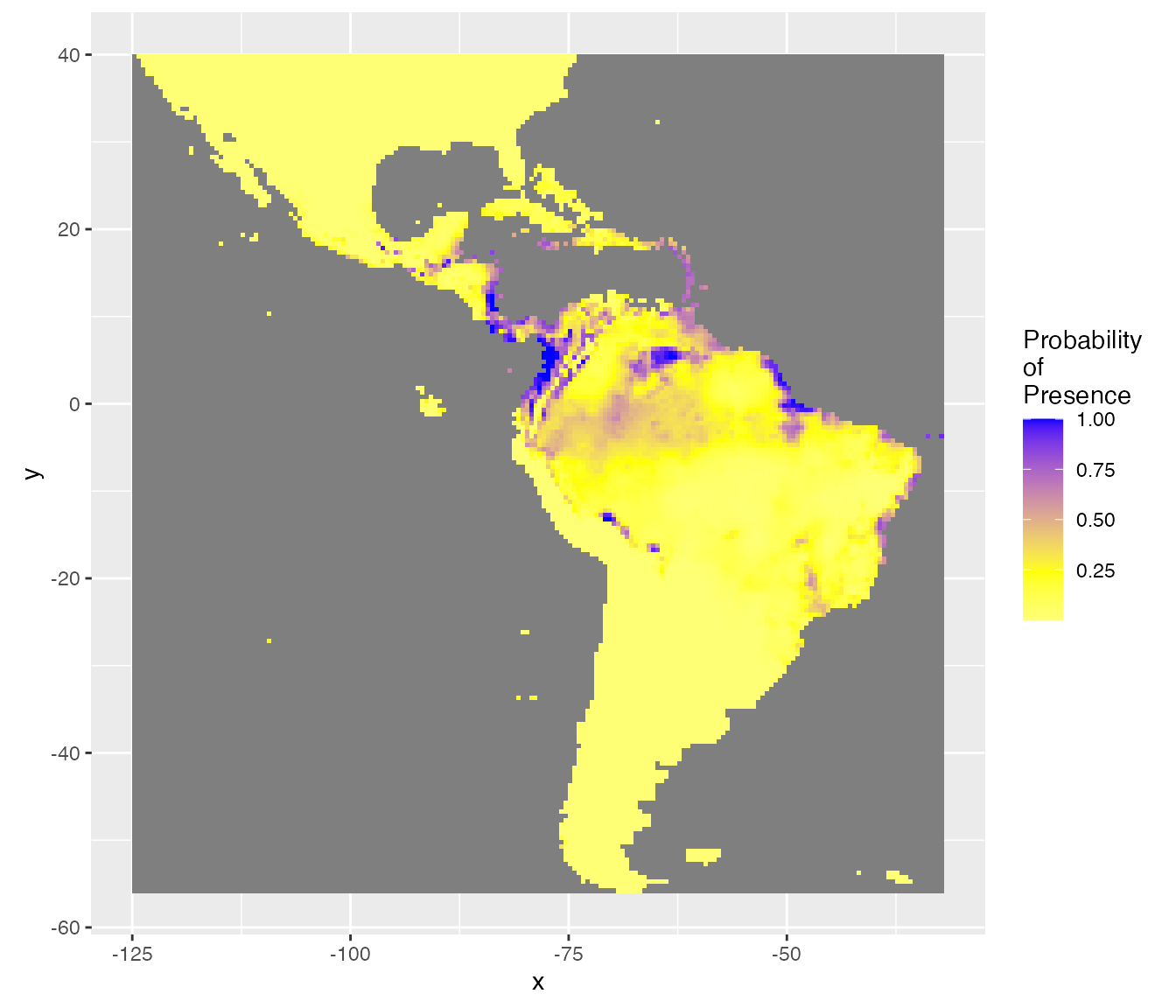
Considering uncertainty of prediction, another output is the probability (%) to be over the best threshold value (thd = 0.24). This gives an idea of the risk to predict a presence, considering the uncertainty on the probability of presence and the best threshold value.
rasterVis::gplot(raster::raster(pred.r, "ProbaSup")) +
geom_tile(aes(fill = value)) +
scale_fill_gradient2("Probability\nto be over\nThreshold",
low = 'white', mid = 'yellow', high = 'forestgreen',
midpoint = 50) +
coord_equal()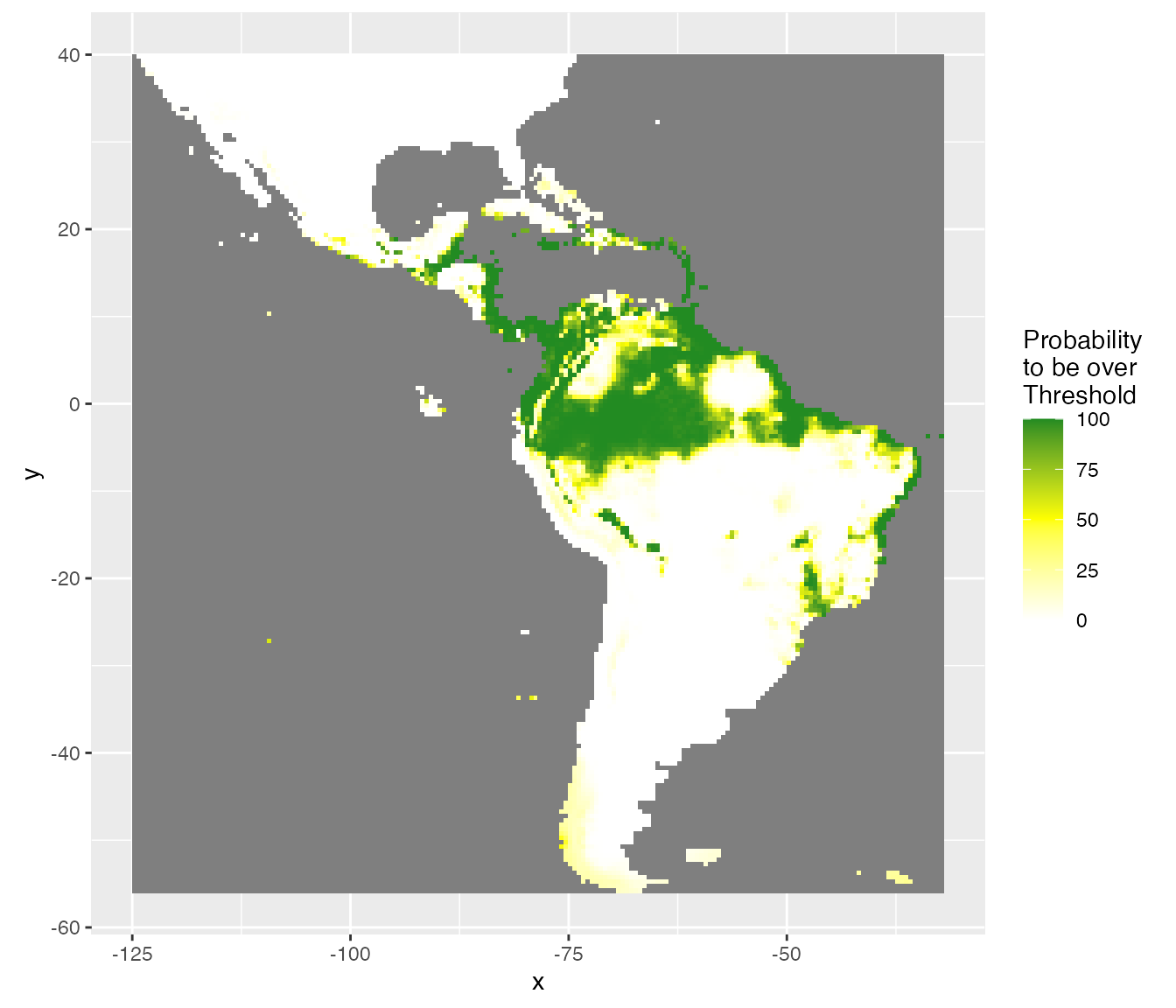
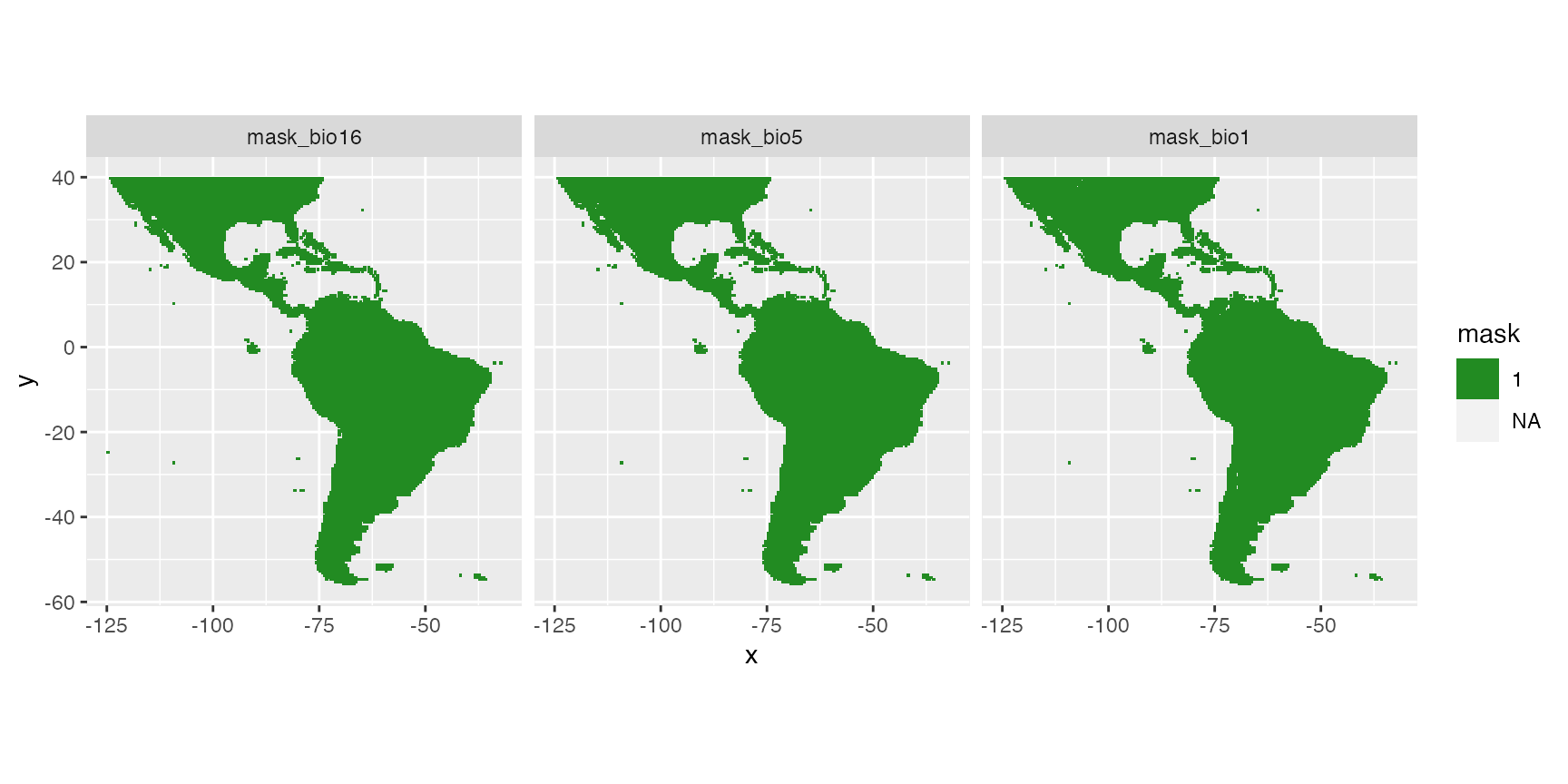
Masks
Finally, a model should not extrapolate out of the range of the data. The Map_predict function retrieves the range of covariates in the dataset used for modelling and create a raster mask for each covariate when out of the range of data observations. In the present example mask is not meaningful because of the absence data covering the entire area.
rasterVis::gplot(raster::dropLayer(pred.r, which(!grepl("mask", names(pred.r))))) +
geom_tile(aes(fill = factor(value))) +
facet_grid(~variable) +
scale_fill_manual("mask", values = c("0" = "red", "1" = "forestgreen")) +
coord_equal()